| 会议详情 |
|

![]() 2017-09-02 14:00 至 2017-09-02 17:00
2017-09-02 14:00 至 2017-09-02 17:00
![]() 200人
200人
活动介绍:
Apache CarbonData是一种基于索引、面向大数据平台的列式数据格式,由华为大数据团队贡献给Apache社区,这也是中国首个贡献给Apache的开源项目。由于当前主流大数据组件应用场景的局限性,CarbonData诞生之初,是希望通过仅保存一份数据来满足多种的应用场景,如:OLAP、顺序存取、随机存取等功能,实现百亿数据级的秒级响应。
为帮助关注CarbonData的开发者全面了解该技术,我们发起了一场关于 Apache CarbonData+Spark 的技术交流会,并邀请了来自美国Databricks、华为、上汽集团等行业顶尖专家,希望通过对Spark SQL使用场景介绍、Spark 2.2核心特性CBO、CarbonData应用实践、以及2.0新技术规划的等技术的解析,让CarbonData使用变得更加简单。
 Apache Spark
Apache Spark
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架。最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。 与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势。 首先,Spark为我们提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。 Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍。 Spark让开发者可以快速的用Java、Scala或Python编写程序。它本身自带了一个超过80个高阶操作符集合。而且还可以用它在shell中以交互式地查询数据。
 华为
华为
华为技术有限公司是一家生产销售通信设备的民营通信科技公司,于1987年正式注册成立,总部位于中国深圳市龙岗区坂田华为基地。 华为是全球领先的信息与通信技术(ICT)解决方案供应商,专注于ICT领域,坚持稳健经营、持续创新、开放合作,在电信运营商、企业、终端和云计算等领域构筑了端到端的解决方案优势,为运营商客户、企业客户和消费者提供有竞争力的ICT解决方案、产品和服务,并致力于使能未来信息社会、构建更美好的全联接世界。2013年,华为首超全球第一大电信设备商爱立信,排名《财富》世界500强第315位。
 InfoQ中国
InfoQ中国
InfoQ成立于2006年。我们为了促进软件开发领域知识与创新的传播而创建了InfoQ。为了实现这个目标,我们致力于提供中立的、由技术实践者主导的会议、内容与在线社区。 为达到这个目的,InfoQ基于实践者驱动的社区模式建立平台,提供新闻、文章、视频演讲和采访等资讯服务,所有的这一切也都是为了研发团队中那些有创新精神的人群:团队领导者、架构师、项目经理、工程总监和高级软件开发人员等。InfoQ全球站正式启动于2006年6月8日,InfoQ中文站正式启动于2007年3月28日。 今天的InfoQ已经是一家国际性的公司,在加拿大、美国、中国和罗马尼亚均设有办公室,运作两大品牌产品:InfoQ网站,以及QCon大会。
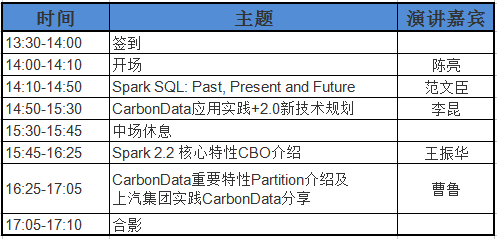
讲师介绍:
个人简介:
Apache Spark PMC member,Spark SQL 开发团队成员。2013年从浙江大学毕业后,一直在进行分布式系统相关的工作。2014年开始接触 Spark,并成为最活跃的代码贡献者之一。2015年正式加入 databricks,成为 databricks 中国分部(筹建中)的第一名员工,主要负责开源社区方面的工作,例如:审查其他社区成员提交的PR,主导 Spark SQL 一些主要功能的设计和研发,定期审计项目代码质量等。
主题摘要:
Spark SQL 作为 Spark 的基础框架,已经有了广泛的用户基础,并且经历了一段漫长的开发历史。本次议题将会带领大家回顾一下 Spark SQL的演进历史,以及目前的现状,和未来的一些展望,帮助大家更好的理解 Spark SQL 的一些设计决策以及使用场景。
个人简介:
李昆,华为技术有限公司大数据软件架构师。2004年加入华为,长期从事电信协议、业务智能化、数据可视化、用户行为分析等系统研究和开发工作。近年致力于大数据技术研究,参与Hadoop、Spark、Alluxio等开源社区,2016年作为CarbonData PMC成员参与Apache CarbonData项目孵化,寻求大数据与一站式分析平台的创新机会点。
主题摘要:
Apache CarbonData是一种新的高性能数据存储,针对当前大数据领域分析场景需求各异而导致的存储冗余问题,CarbonData提供了一种新的融合数据存储方案,以一份数据同时支持大数据分析的多种应用场景(如:“任意维度组合的数据查询分析、快速扫描、详单查询、数据更新删除等”),并通过多级索引、字典编码、列存等特性提升了IO扫描和计算性能,实现百亿数据级秒级响应。`
CarbonData开源后,受到全球大数据技术爱好者高度关注;截止到目前为止,全球已有100+开发者参与了代码贡献,有10+家企业上线生产系统。
个人简介:
王振华,现任华为公司研究工程师,致力于构建高性能大数据查询分析平台。在此之前,博士毕业于浙江大学计算机科学与技术学院,研究方向涉及空间数据库、信息检索、数据挖掘。
主题摘要:
在Spark SQL的Catalyst优化器中,许多基于规则的优化技术已经实现,但优化器本身仍然有很大的改进空间。例如,没有关于数据分布的详细列统计信息,因此难以精确地估计过滤(filter)、连接(join)等数据库操作符的输出大小和基数 (cardinality)。由于不准确的估计,它经常导致优化器产生次优的查询执行计划。
在Spark 2.2中,在Spark SQL引擎内添加了一个基于成本的优化器框架,此框架计算每个数据库操作符的基数和输出大小。通过可靠的统计和精确的估算,能够在这些领域做出好的决定:选择散列连接(hash join)操作的正确构建端(build side),选择正确的连接算法(如broadcast hash join与 shuffled hash join),调整连接的顺序等等。在这次演讲中,我们将展示Spark SQL的新的基于成本的优化器框架及其对TPC-DS查询的性能影响。
个人简介:
现任上汽集团数据业务部大数据平台开发经理,目前主要专注于大数据平台架构,数据存储、压缩、索引以及实时流数据处理等领域的研究及应用。曾负责某金融行业公司ETL、BI系统开发,某互联网电商公司的数据仓库容量管理,性能调优等。热衷开源技术研究,Apache CarbonData社区贡献者。
主题摘要:
CarbonData的partition特性将在Apache CarbonData 1.2.0版本里正式发布,此特性将显著提升大数据查询性能。上汽集团大数据将CarbonData作为平台基础组件,以应对迅猛增长的数据量,本议题将分享上汽集团在CarbonData项目的实践和测试数据。
免费参加
相关会议

2026-04-10上海
2026-11-20北京



