| 会议详情 |
|

推荐会议:2026Agentic AI Summit 超级智能体系统架构峰会
发票类型:增值税普通发票 增值税专用发票
一、课程简介
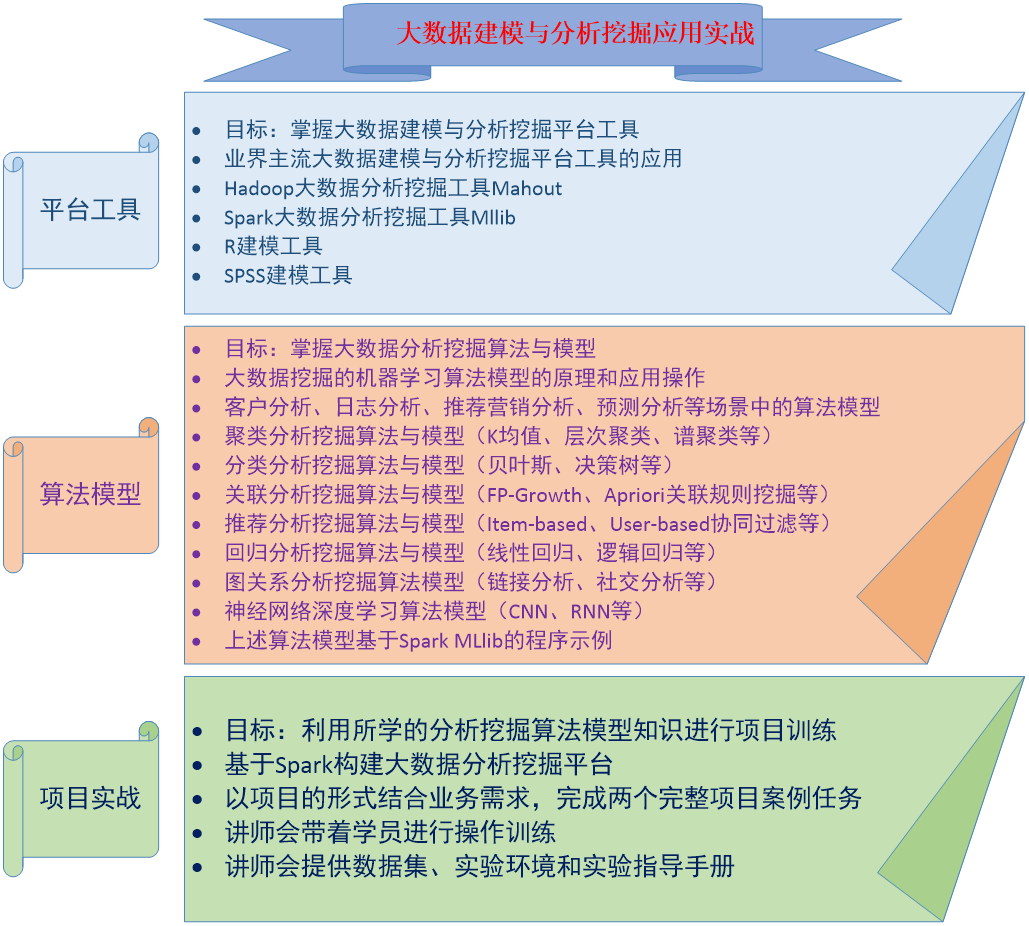
大数据建模与分析挖掘技术已经逐步地应用到新兴互联网企业(如电子商务网站、搜索引擎、社交网站、互联网广告服务提供商等)、银行金融证券企业、电信运营等行业,给这些行业带来了一定的数据价值增值作用。
本次课程面向有一定的数据分析挖掘算法基础的工程师,带大家实践大数据分析挖掘平台的项目训练,系统地讲解数据准备、数据建模、挖掘模型建立、大数据分析与挖掘算法应用在业务模型中,结合主流的Hadoop与Spark大数据分析平台架构,实现项目训练。
结合业界使用最广泛的主流大数据平台技术,重点剖析基于大数据分析算法与BI技术应用,包括分类算法、聚类算法、预测分析算法、推荐分析模型等在业务中的实践应用,并根据讲师给定的数据集,实现两个基本的日志数据分析挖掘系统,以及电商(或内容)推荐系统引擎。
本课程基本的实践环境是Linux集群,JDK1.8, Hadoop 2.7.*,Spark 2.1.*。
学员需要准备的电脑最好是i5及以上CPU,4GB及以上内存,硬盘空间预留50GB(可用移动硬盘),基本的大数据分析平台所依赖的软件包和依赖库等,讲师已经提前部署在虚拟机镜像(VMware镜像),学员根据讲师的操作任务进行实践。
本课程采用技术原理与项目实战相结合的方式进行教学,在讲授原理的过程中,穿插实际的系统操作,本课程讲师也精心准备的实际的应用案例供学员动手训练。
课程时间及地址:5月26日-29日 深圳
二、培训目标
1.本课程让学员充分掌握大数据平台技术架构、大数据分析的基本理论、机器学习的常用算法、国内外主流的大数据分析与BI商业智能分析解决方案、以及大数据分析在搜索引擎、广告服务推荐、电商数据分析、金融客户分析方面的应用案例。
2.本课程强调主流的大数据分析挖掘算法技术的应用和分析平台的实施,让学员掌握主流的基于大数据Hadoop和Spark、R的大数据分析平台架构和实际应用,并用结合实际的生产系统案例进行教学,掌握基于Hadoop大数据平台的数据挖掘和数据仓库分布式系统平台应用,以及商业和开源的数据分析产品加上Hadoop平台形成大数据分析平台的应用剖析。
3.让学员掌握常见的机器学习算法,深入讲解业界成熟的大数据分析挖掘与BI平台的实践应用,并以客户分析系统、日志分析和电商推荐系统为案例,串联常用的数据挖掘技术进行应用教学。
三、培训人群
1.大数据分析应用开发工程师
2.大数据分析项目的规划咨询管理人员
3.大数据分析项目的IT项目高管人员
4.大数据分析与挖掘处理算法应用工程师
5.大数据分析集群运维工程师
6.大数据分析项目的售前和售后技术支持服务人员
四、培训特色
定制授课+ 实战案例训练+ 互动咨询讨论
(说明:讲师会提供虚拟机镜像,并把Hadoop,Spark等系统提前部署在虚拟机中,分析挖掘平台构建在Hadoop与Spark之上,学员自带笔记本,运行虚拟机,并利用同样的镜像启动多台虚拟机,构建实验集群,镜像会提前给学员)
 中国信息化人才培训中心
中国信息化人才培训中心
天博信通-中国信息化人才培训中心率先在国内开展高级软件架构等IT高端培训的公开课。多年来持续不断的投入精力创新课程体系,至今已在国内开展公开课培训的课程达十几门,分别涵盖、云计算、大数据、软件架构、软件设计、高级UI设计、项目管理、质量管理、需求工程、运营管理等领域,也根据企事业单位的实用需求, 通过定制培训方案,培训后的技术服务,将企业单位的信息化投资的效益发挥到最高点。目前中心已经与几百家企事业单位建立了长期的培训合作关系, 深得用户信赖和好评。
详细大纲与培训内容
|
两个完整的项目任务和实践案例(重点) |
1.日志分析建模与日志挖掘项目实践 a)Hadoop,Spark,并结合ELK技术构建日志分析系统和日志数据仓库 b)互联网微博日志分析系统项目 2.推荐系统项目实践 a)电影数据分析与个性化推荐关联分析项目 b)电商购物篮分析项目 Hadoop,Spark,可结合Oryx分布式集群在个性化推荐和精准营销项目。 |
项目的阶段性步骤贯穿到三天的培训过程中,第三天完成整个项目的原型 |
培训内容安排如下:
|
时间 |
内容提要 |
授课详细内容 |
实践训练 |
|
第一天 |
业界主流的数据仓库工具和大数据分析挖掘工具 |
|
配置数据仓库工具Hadoop Hive和SparkSQL
部署数据分析挖掘工具Hadoop Mahout和Spark MLlib |
|
大数据分析挖掘项目的数据集成操作训练 |
|
项目数据集加载ETL到Hadoop Hive数据仓库并建立多维模型 |
|
|
基于Hadoop的大型数据仓库管理平台— |
|
利用HIVE构建大型数据仓库项目的操作训练实践 |
|
|
Spark大数据分析挖掘平台实践操作训练 |
|
|
|
|
第二天 |
聚类分析建模与挖掘算法的实现原理和技术应用 |
|
基于Spark MLlib的聚类分析算法,实现日志数据集中的用户聚类 |
|
分类分析建模与挖掘算法的实现原理和技术应用 |
|
基于Spark MLlib的分类分析算法模型与应用操作 |
|
|
关联分析建模与挖掘算法的实现原理和技术应用 |
|
基于Spark MLlib的关联分析操作 |
|
|
第三天 |
推荐分析挖掘模型与算法技术应用 |
|
推荐分析实现步骤与操作(重点) |
|
回归分析模型与预测算法 |
|
回归分析预测操作例子 |
|
|
图关系建模与分析挖掘及其链接分析和社交分析操作 |
|
图数据的分析挖掘操作,实现微博数据集的社交网络建模与关系分析 |
|
|
神经网络与深度学习算法模型及其应用实践 |
|
基于Spark或TensorFlow神经网络深度学习库实现文本与图片数据挖掘 |
|
|
项目实践 |
|
项目数据集和详细的实验指导手册由讲师提供 |
|
|
|
培训总结 |
|
讨论交流 |
|
第四天 |
学员考试与业界交流 |
||
师资力量
周老师:男,中国科学院通信与信息系统专业博士。北京邮电大学移动互联网与信息化实验室特聘研究员、对外经贸大学信息学院特聘兼职教师、中国移动集团高级培训讲师,长期从事大数据、4G、移动互联网安全、管理及大数据精确营销等研究方向。国内顶级信息系统架构师,金牌讲师,技术顾问,移动开发专家。拥有丰富的通信信息系统设计、开发经验及培训行业经验,先后为全国超过15家省移动公司,超过30家地市移动公司有过项目开发合作及授课,担任多个大型通信项目的总师。
张老师:阿里大数据高级专家,国内资深的Spark、Hadoop技术专家、虚拟化专家,对HDFS、MapReduce、HBase、Hive、Mahout、Storm、spark和openTSDB等Hadoop生态系统中的技术进行了多年的深入的研究,更主要的是这些技术在大量的实际项目中得到广泛的应用,因此在Hadoop开发和运维方面积累了丰富的项目实施经验。近年主要典型的项目有:某电信集团网络优化、中国移动某省移动公司请账单系统和某省移动详单实时查询系统、中国银联大数据数据票据详单平台、某大型银行大数据记录系统、某大型通信运营商全国用户上网记录、某省交通部门违章系统、某区域医疗大数据应用项目、互联网公共数据大云(DAAS)和构建游戏云(Web Game Daas)平台项目等。
培训费用及须知
培训费7800元/人。(含培训费、资料费、考试费、证书费、讲义费等)。需要住宿学员请提前通知,可统一安排,费用自理。
颁发证书
参加相关培训并通过考试的学员,可以获得:
工业和信息化部颁发的-大数据挖掘高级工程师职业技能证书。该证书可作为专业技术人员职业能力考核的证明,以及专业技术人员岗位聘用、任职、定级和晋升职务的重要依据。
注:请学员带二寸彩照2张(背面注明姓名)、身份证复印件一张。
相关会议

2026-01-16北京
2026-02-06郑州